Python笔记
.
函数参数传递
Python函数参数可以包含一个*name和一个**name,其中*name可以接收多余的位置参数,并写到一个元组里,**name可以接收一个字典,在写程序时*name必须写在**name前
特殊参数

/前的参数为仅限位置参数,*后的参数为仅限关键字参数
解包参数列表
*解包列表,**解包字典
Lambda
语法
1 | lambda argument_list:expresion |
数据结构
列表
list.append(x)
在列表的末尾添加一个元素
list.extend(iterable)
使用可迭代对象(如字符,列表)等扩展列表
list.insert(i,x)
在i位置处插入一个元素x
list.remove(x)
移除列表中第一个值为x的值
list.pop([i])
删除列表中给定位置的元素并返回它
list.clear()
删除列表中的所有元素
list.index(x[,start[,end]])
返回列表中第一个值为x的从零开始的索引,start和end将搜索限制为列表的特定的子序列,最终返回的值还是相对于整个序列开始计算的。
list.count(x)
返回元素x在列表中出现的次数
list.sort(*,key=None,reverse=False)
对列表中的元素进行排序
list.reverse()
反转列表中的元素
list.copy()
返回列表中的浅拷贝
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如list(zip([1,2,3],[4,5,6],[7,8,9]))返回[(1,4,7),(2,5,8),(3,6,9)]
元组
一个元组由几个被逗号隔开的值组成,例如
1 | t=12345,54321,'hello' |
如果想创建0个元素或1个元素的元组,可以通过以下代码实现
1 | empty=()#创建0个元素的元组 |
注意:不能通过圆括号包围一个元素来建立只有一个元素的元组
一些花里胡哨的操作
t=1,2,3
x,y,z=t
集合
集合是由不重复元素组成的无序的集,可以通过花括号或set()创建集合,要创建空集合只能通过set()
1 | test={1,2,3,4,5,4,4,3,2,1} |
类似于列表推导式,集合也支持推导式形式
1 | a = {x for x in 'abracadabra' if x not in 'abc'} |
字典
字典以关键字为索引,关键字必须为不可变对象,如数字、字符串或元组;字符串是键:值对的集合,键必须是唯一的,可以用del来删除一个键值对。
可以使用list(d)来列出d字典中所有键的列表(按插入次序排列)
1 | tel={'jack':4098,'sape':4139} |
dict()构造函数可以直接从键值对序列里创建字典
1 | dict([('sape', 4139), ('guido', 4127), ('jack', 4098)]) |
也可以这样使用
1 | dict(sape=4139, guido=4127, jack=4098) |
可以用items()方法将关键字和值一块取出
逆向循环一个序列,可以使用reversed()函数
去除重复元素可用set(),返回一个集合,再用sorted()输出排好序的列表
条件控制
in和not in可以校验一个值是否在(或不在)一个序列里,is和is not可以比较是不是同一个操作对象
比较操作可以传递,如a<b==c会比较a是否小于b并且b是否等于c
and和or是短路操作符,一旦符合要求,不会继续执行后边的判断,当用作普通值而非布尔值时,
短路操作符的返回值通常是最后一个变量。
1 | string1, string2, string3 = '', 'Trondheim', 'Hammer Dance' |
python在表达式中赋值必须用:=
比较
见代码
1 | (1, 2, 3) < (1, 2, 4) |
模块
模块名存放在__name__里
几种调入方式
1 | import module_name1 |
每个模块在每个解释器会话中只被导入一次,如果你更改了你的模块,则必须重新启动解释器,或者,如果它只是一个要交互式地测试的模块,请使用 importlib.reload(),例如 import importlib; importlib.reload(modulename)。
执行模块的话__name__为__main__
标准模块
sys.ps1和sys.ps2主要用作主要和辅助提示的字符串
1 | import sys |
sys.path 变量是一个字符串列表,用于确定解释器的模块搜索路径。
dir()函数
函数 dir() 用于查找模块定义的名称。它返回一个排序过的字符串列表
如果没有参数,dir() 会列出当前定义的名称
1 | dir() |
dir() 不会列出内置函数和变量的名称。它们的定义是在标准模块 builtins 中:
1 | import builtins |
包
包是一种通过用”带点号的模块名“构造 Python 模块命名空间的方法,使用加点的模块名可以使多模块软件包的作者不必担心彼此的模块名称一样。
一个包中必须含有__init__.py才能称为包
从包中导入*
1 | from package.submodule import * |
如果submodule中的__init__.py中定义了名为__all__的列表,则根据此列表中的元素导入,若没有定义这个变量,则导入子模块中定义的所有变量
子包参考
当包构成子包时,可以使用绝对导入来引用兄弟包的子模块,也可以使用相对导入,如
1 | from . import echo |
注意:相对导入是基于当前模块的名称进行导入的,python的主模块名称总为__main__,故主模块必须始终使用绝对导入。
输入输出
格式化字符串
在字符串的开头加上f或F,在此字符串中可以使用{}包裹的变量,如
1 | year='2022' |
字符串类型有format()方法,花括号内内容为{字段名!转换字段:格式说明符}
格式说明符内内容为[[填充]对齐方式][正负号][#][0][宽度][分组选项][.精度][类型码]具体使用方法可参考https://blog.csdn.net/jpch89/article/details/84099277
str和repr
str可以将其它类型的数据转化为人可读的格式,repr则将字符转换为解释器可读的格式。
手动格式化字符串
ljust(n)和rjust(n)左对齐和右对齐并补空格至n位,center(n)居中对齐
str.zfill() ,它会在数字字符串的左边填充零。能识别正负号:
1 | '12'.zfill(5) |
旧的字符串格式方法
% 运算符(求余)也可用于字符串格式化。给定 ‘string’ % values,则 string 中的 % 实例会以零
个或多个 values 元素替换。此操作通常被称为字符串插值。
1 | print('This is a test number %5.3f %3.5f' % (54,45)) |
读写文件
1 | f=open('file','w') |
| 字符 | 含义 |
|---|---|
| w | 只能写入 |
| r | 只能读取 |
| a | 打开文件追加内容 |
| r+ | 读写 |
默认为’r’
读文件的方法
f.read(size)若以文本方式打开,返回size个字符,若以二进制方式打开,返回size个字节,若到达文件末尾返回空字符
f.readline()从文件中读取一行,换行符(\n)留在字符串的末尾,如果 f.readline() 返回一个空的字符串,则表示已经到达了文件末尾
要从文件中读取行,可以循环遍历文件对象,这是内存高效,快速的,并简化代码:
1 | for line in f: |
如果想以列表方式读取文件所有行可用list(f)或f.readlines()
f.tell()返回一个整数,这个数字为文件对象在文件中的位置
f.seek(offset,whence)改变文件对象的位置,offset提供偏移量,whence提供参考点,0表示开头,1表示使用当前文件位置,2表示使用文件末尾,默认为0
异常处理
1 | while True: |
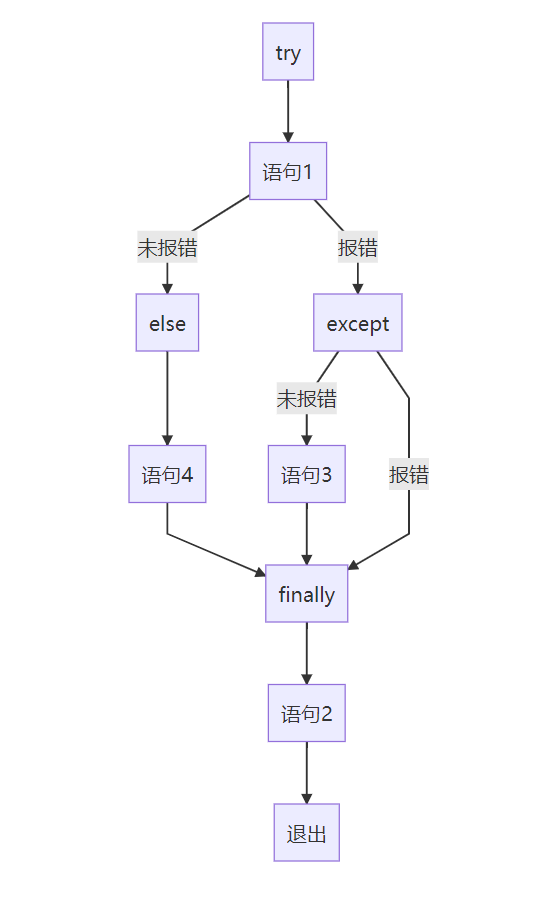
首先,执行try子句,若无异常,跳过except,若异常和except后的内容一样,则执行except后的子句
若except后不跟异常类型,则可以处理所有异常
try后可跟else子句,使用时必须放在except后面
1 | for arg in sys.argv[1:]: |
try不出错则执行else中的内容
异常链
1 | try: |
报错信息:
1 | Traceback (most recent call last): |
可以使用from使报错信息更明确
1 | try: |
报错信息:
1 | Traceback (most recent call last): |
可以使用from None使只报Exception里的错
1 | try: |
报错信息
1 | Traceback (most recent call last): |
用户自定义异常
异常通常应该直接或间接由Exception类派生
1 | class Error(Exception): |
finally语句
无论try有没有异常,都会执行finally后的语句
若try无异常,则try的语句执行完后执行finally中的语句
若try出现异常,则在报错前先执行finally中的语句然后报错
1 | graph TB |
预清理操作
1 | with open('test.txt') as f: |
执行完操作以后,f文件对象会被自动关闭
类
global and nonlocal
关于global和nonlocal的使用方法,可以参考这篇博客https://blog.csdn.net/xCyansun/article/details/79672634
定义类
1 | class ClassName: |
类对象支持属性引用和实例化
1 | class ClassName: |
类的变量不能为mutable类型
继承
Python有两个内置函数可被用于继承机制
isinstance()来检查一个实例的类型
1
2
3
4
5
6class MyClass():
... pass
...
x=MyClass()
isinstance(x,MyClass)
Trueissubclass()来检查一个类是否是另一个类的子类
1
2issubclass(bool,int)
True
私有变量
带有一个下划线的名称应当看作是API的非共有部分(如_spam)
名称改写:任何形式为__spam(至少有两个前缀下划线,至多一个后缀下划线)的文本将被替换为_classname__spam
迭代器与生成器
迭代器,对一个对象使用iter(),返回迭代器,迭代器有next()方法,可以返回迭代器的下一个值,如果到达末尾,则返回StopIteration
生成器表达式语法类似于列表推导式,但外层是圆括号而非方括号
标准库
操作系统接口
1 | import os |
文件通配符
1 | import glob |
命令行参数
1 | import sys |
错误输出重定向和程序终止
sys模块具有stdin、stdout、stderr属性,终止脚本的最直接的方法是使用sys.exit()
正则表达式
re模块
数学
math模块,random模块,statistics模块
日期和时间
datetime模块
数据压缩
zlib, gzip, bz2, lzma, zipfile 和 tarfile模块
虚拟环境
创建虚拟环境
1 | python -m venv test#test为文件夹名称 |
激活
1 | .\test\Scripts\activate.bat |
pip
命令
install 安装
download 下载
uninstall 卸载
freeze 将安装的包列表导出成想要的格式
list 显示安装的包列表
show 显示包的信息
check 检查包依赖
config
search 在Pypi上寻找包
cache
index
wheel
hash
completion
debug
help 帮助
install
pip install numpy
pip install numpy==1.20.1
pip install —upgrade requests
show
$pip show numpy
Name: numpy
Version: 1.21.5
Summary: NumPy is the fundamental package for array computing with Python.
Home-page: https://www.numpy.org
Author: Travis E. Oliphant et al.
Author-email:
License: BSD
Location: d:\pyth39\lib\site-packages
Requires:
Required-by: h5py, Keras-Preprocessing, librosa, matplotlib, numba, opencv-python, opt-einsum, pandas, resampy, scikit-learn, scipy, seaborn, tensorboard, tensorflow, torchvision, umap-learn, visdom, wordcloud
list
$pip list
Package Version
-————- ———-
pip 21.3.1
setuptools 56.0.0
freeze
pip freeze > requirements.txt
然后可以使用
pip install -r requirements.txt
附录
交互式启动文件
在Windows的环境变量中添加名为PYTHONSTARTUP的项,将值指向一个py文件,这样,当进行交互式操作时,会首先执行这个所指向的文件
定制模块
首先使用site模块获得用户自定义site-package的位置
1 | import site |
然后在得到的文件夹建立一个usercustomize.py的文件,这样每次启动python都会首先执行这个文件,与PYTHONSTARTUP不同的是,usercustomize.py文件的命名空间与交互式窗口不同
sitecustomize.py与usercustomize.py作用相同,不过它比usercustomize.py先调用。
此外,可用python -s禁用自动导入